This post is based on a lightning talk I gave on 2015, at GruPy-SP (July/15) in Sao Paulo.
What’s the matter of having time-consuming tasks on the server side?
Every time the client makes a request, the server has to read the request, parse the received data, retrieve or create something into the database, process what the user will receive, renders a template and send a response to the client. That’s usually what happens in a Django app.
Depending on what you are executing on the server, the response can take too long and it leads to problems such as poor user experience or even a time-out error. It’s a big issue. Loading time is a major contributing factor to page abandonment. So, slow pages lose money.
There’s a lot of functions that can take a long time to run, for instance, a large data report requested by a web client, emailing a long list or even editing a video after it’s uploaded on your website.
Real Case:
That’s a problem that I’ve face once when I was creating a report. The report took around 20 minutes to be sent and the client got a time-out error and obviously, nobody wants to wait 20 minutes for getting something. So, to handle this I’d have to let the task run in the background. (On Linux, you can do this putting a & at the end of a command and the OS will execute the command in the background)
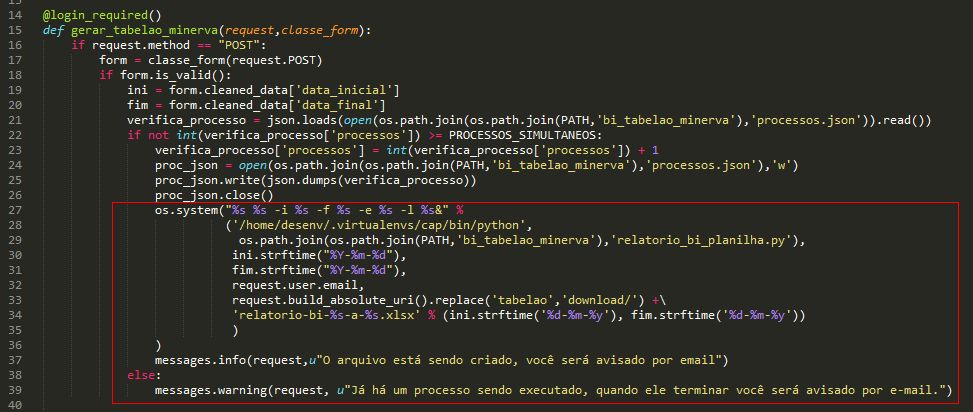
It looks like the worst code ever.
Celery – the solution for those problems!
Celery is a distributed system to process lots of messages. You can use it to run a task queue (through messages). You can schedule tasks on your own project, without using crontab and it has an easy integration with the major Python frameworks.
How does celery work?
Celery Architecture Overview. (from this SlideShare)
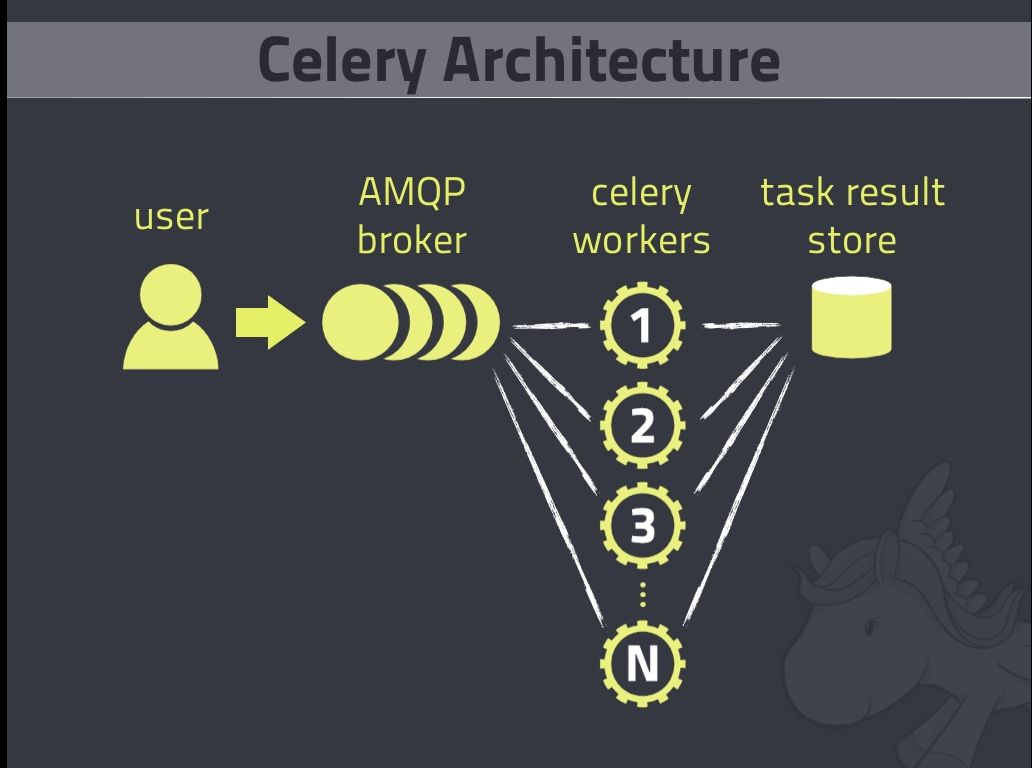
- The User (or Client or Producer) is your Django Application.
- The AMPQ Broker is a Message Broker. A program responsible for the message queue, it receives messages from the Client and delivers it to the workers when requested. For Celery the AMPQ Broker is generally RabbitMQ or Redis
- The workers (or consumers) that will run your tasks asynchronously.
- The Result Store, a persistent layer where workers store the result of tasks.
The client produces messages, deliver them to the Message Broker and the workers read this messages from the broker, execute them and can store the results on a Memcached, RDBMS, MongoDB, whatever the client can access later to read the result.
Installing and configuring RabbitMQ
There is a lot of examples on How to Use Celery with Redis. I’m doing this with RabbitMQ.
- Install RabbitMQ
sudo apt-get install rabbitmq-server - Create a User, a virtual host and grant permissions for this user on the virtual host:
sudo rabbitmqctl add_user myuser mypassword sudo rabbitmqctl add_vhost myvhost sudo rabbitmqctl set_permissions -p myvhost myuser ".*" ".*" ".*"
Installing and configuring Celery
pip install celery
In your settings.py:
#Celery Config
BROKER_URL = 'amqp://guest:guest@localhost:5672//'
CELERY_ACCEPT_CONTENT = ['json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'In your project’s directory (the same folder of settings.py), creates a celery.py file as following.
from __future__ import absolute_import
import os
from celery import Celery
from django.conf import settings
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'nome_do_proj.settings')
app = Celery('nome_do_proj')
# Using a string here means the worker will not have to
# pickle the object when using Windows.
app.config_from_object('django.conf:settings')
app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)This autodiscover_tasks allows your project to find the asynchronous task of each Django App. In the same directory, you have to modify your __init__.py:
from __future__ import absolute_import
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_appCreating tasks for your app
In your app’s directory, put a tasks.py:
from __future__ import absolute_import
from celery import shared_task
from reports import generate_report_excel
@shared_task # Use this decorator to make this a asyncronous function
def generate_report(data_inicial, data_final, email):
generate_report_excel(
ini_date = ini_date,
final_date = final_date,
email = email
)
Now you just have to import this function anywhere you want and call the delay method, that was added by the shared_task decorator.
from tasks import generate_report
@login_required()
def my_view(request):
...
generate_report.delay(ini_date, final_date, email)
return "You will receive an email when the report is done"
Running celery workers
Now you have to run the celery workers so they can execute the tasks getting the messages from the RabbitMQ Broker. By default, celery starts one worker per available CPU. But you can change it using the concurrency parameter (-c)
celery --app=nome_projeto worker --loglevel=INFO
And your screen will look like this:
In another terminal you can open the shell and call your task to see it working:
In [1]: from app.tasks import generate_report
In [2]: generate_report("2012-01-01", "2015-03-14", "[email protected]")
And you will see something like this on Celery:

Deploying Celery
To use celery in production you’ll need a process control system like Supervisor
To install supervisor:
sudo apt-get install supervisorNow you have to create a configuration file for celery in /etc/supervisor/conf.d/
[program:celery]
command=/home/deploy/.virtualenvs/my_env/bin/celery --app=proj_name worker --loglevel=INFO
directory=/home/deploy/webapps/django_project
user=user_name
autostart=true
autorestart=true
redirect_stderr=trueNow inform Supervisor that there is a new process:
sudo supervisorctl reread
sudo supervisorctl updateAnd now starts celery on supervisor:
sudo supervisorctl start celeryMy presentation in Brazilian Portuguese:
Originally posted in Portuguese
Sources:
https://speakerdeck.com/allisson/tarefas-assincronas-com-django-e-celery?#stargazers
http://www.slideshare.net/idangazit/an-introduction-to-celery
http://docs.celeryproject.org/en/latest/django/first-steps-with-django.html#using-celery-with-django
http://www.onurguzel.com/supervisord-restarting-and-reloading/
Webmentions
[…] If you don’t know how to use celery, read this post first: http://3.230.47.72/executing-time-consuming-tasks-asynchronously-with-django-and-celer… […]
[…] If you don’t know how to use celery, read this post first: http://3.230.47.72/executing-time-consuming-tasks-asynchronously-with-django-and-celer… […]
[…] If you don’t know how to use celery, read this post first: http://3.230.47.72/executing-time-consuming-tasks-asynchronously-with-django-and-celery… […]
[…] This post is based on a lightning talk I gave on 2015, at GruPy-SP (July/15) in Sao Paulo. What’s the matter of having time-consuming tasks on the server side? Every time the client makes a request, the server has to read the request, parse the received d… Read more […]